The Audacity of Static Recompilation


Static binary recompilation represents a significant advancement in cross-platform software compatibility technology. This approach performs instruction translation prior to runtime into a 'recompilable' format. This produces native executables that operate directly on target architectures without the performance overhead inherent in traditional dynamic or JIT emulation systems.
XenonRecomp's successful implementation of Xbox 360 static recompilation demonstrates the practical viability of this technology for complex legacy software. The project has achieved the first working conversion of PowerPC Xbox 360 executables into native x86 binaries, delivering performance improvements while maintaining complete compatibility with original software behavior.
Technical Foundation and Historical Development
Static recompilation technology builds upon decades of compiler research and optimization theory. The foundational work in control flow analysis was established by Frances E. Allen in her seminal 1970 research on "Control Flow Analysis," which introduced fundamental techniques for understanding program structure that remain essential to modern binary translation systems. Gary Kildall's development of XLT86 in 1981 provided the first practical demonstration of optimizing assembly code translation, converting Intel 8080 source code to 8086 format through sophisticated data flow analysis techniques.
It remained more-or-less a decomplication tactic to generate psuedocode rather than as a mechanism to translate binary executables from one architecture to another. Until the Nintendo 64 modding scene provided the initial breakthrough in practical static recompilation through the N64: Recompiled project.
This N64: Recompiled project demonstrated that MIPS binaries could be systematically converted to C code and compiled for contemporary platforms, establishing the fundamental workflow of binary analysis, intermediate representation generation, and target code emission that subsequent recompilation efforts have adopted.
Xbox 360 Architectural Challenges
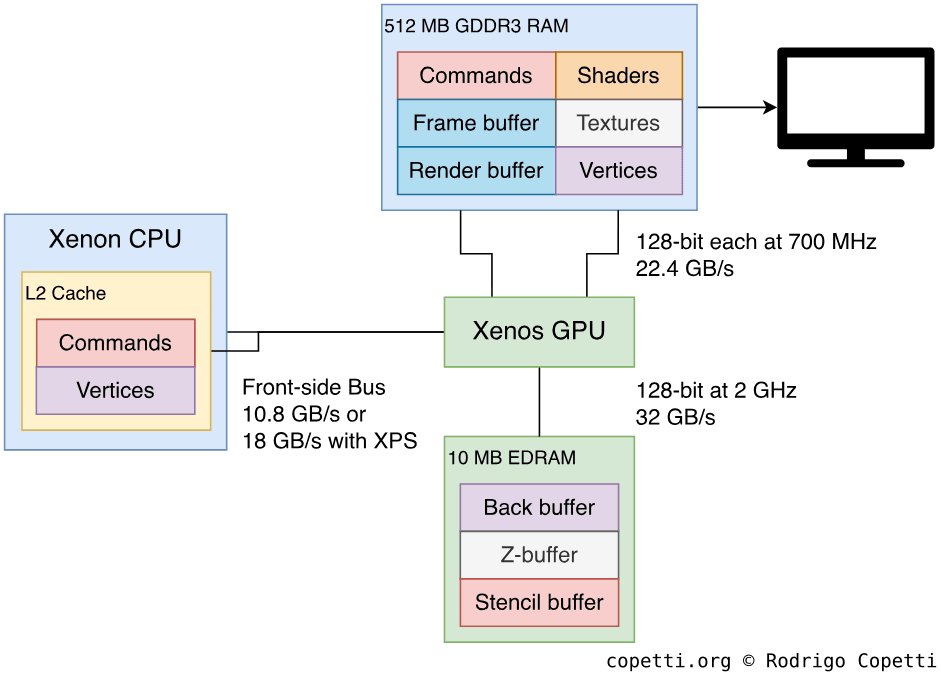
The Microsoft Xbox 360 presents a formidable emulation target due to its deeply customized and heterogeneous architecture. Emulating this system on a standard x86-64 PC requires overcoming profound disparities in processor design, memory hierarchy, and data representation. These challenges are not merely a matter of raw performance but of accurately modeling the complex interactions between several unique components: the triple-core Xenon CPU, the proprietary Xenos GPU, and a unified memory architecture, all interconnected by a high-speed coherent bus.
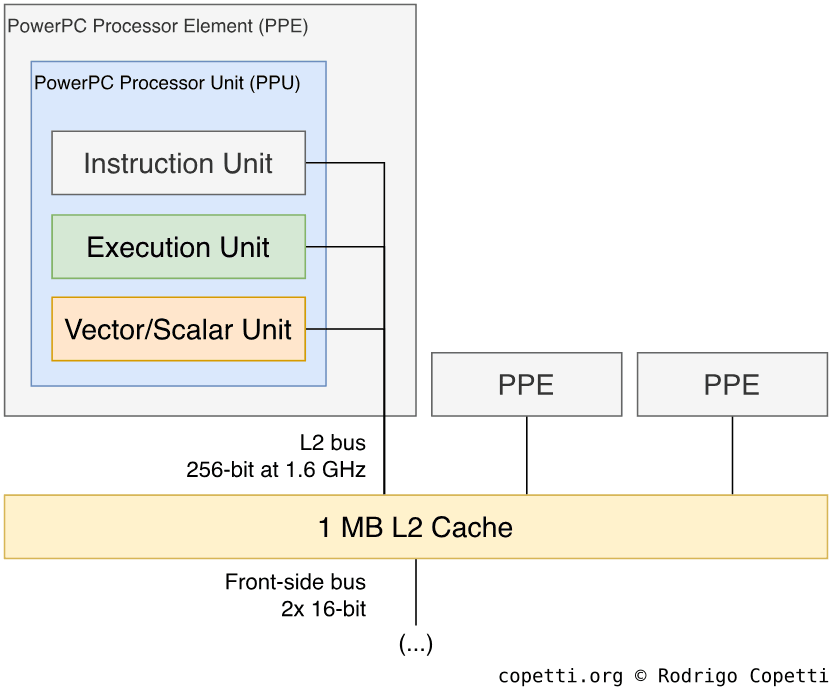
The Xenon CPU and Register Pressure
The IBM PowerPC-based Xenon CPU is a defining source of complexity. Its three cores, operating at 3.2 GHz, utilize in-order execution to prioritize power efficiency. To compensate for the potential stalls inherent in an in-order design, each core supports two simultaneous hardware threads (SMT), requiring an emulator to manage and synchronize six logical threads.
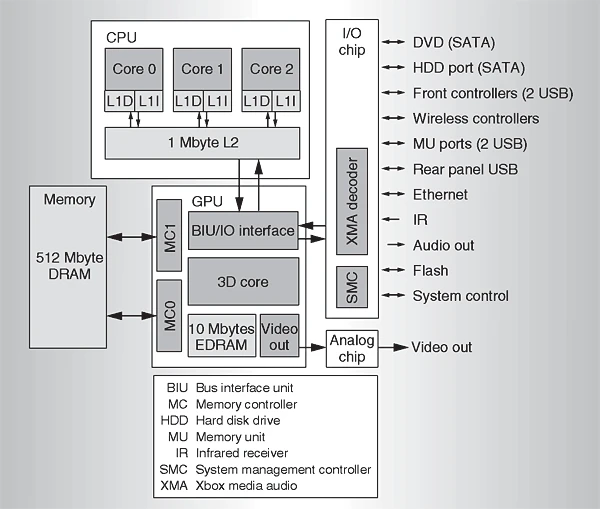
The CPU's extensive register file immediately compounds this complexity. The PowerPC ISA provides 32 general-purpose registers (GPRs)—double the 16 available in x86-64—creating a significant register allocation challenge that often forces an emulator to "spill" registers to memory, incurring a performance penalty. This is further exacerbated by the VMX128 extension, which equips each hardware thread with 128 dedicated 128-bit vector registers. A single core must therefore manage 256 active vector registers, presenting a formidable mapping problem when translating to the mere 16 architectural vector registers (XMM/YMM) available on a host x86 CPU.
Another fundamental, low-level challenge arises from the differing byte-ordering schemes of the PowerPC and x86 architectures. The Xbox 360's big-endian memory ordering conflicts with the x86-64's little-endian design. This necessitates systematic byte-swapping for nearly every load and store operation, introducing a pervasive performance overhead that must be addressed at the compilation level.

The Unified Memory Architecture (UMA)
The Xenon CPU and ATI Xenos GPU are not discrete components; they are intricately linked via a proprietary, high-bandwidth coherent bus known as the XBAR (Crossbar). This interconnect is the foundation of the console's unified memory architecture (UMA), a 512MB pool of GDDR3 RAM shared coherently between the CPU and GPU.
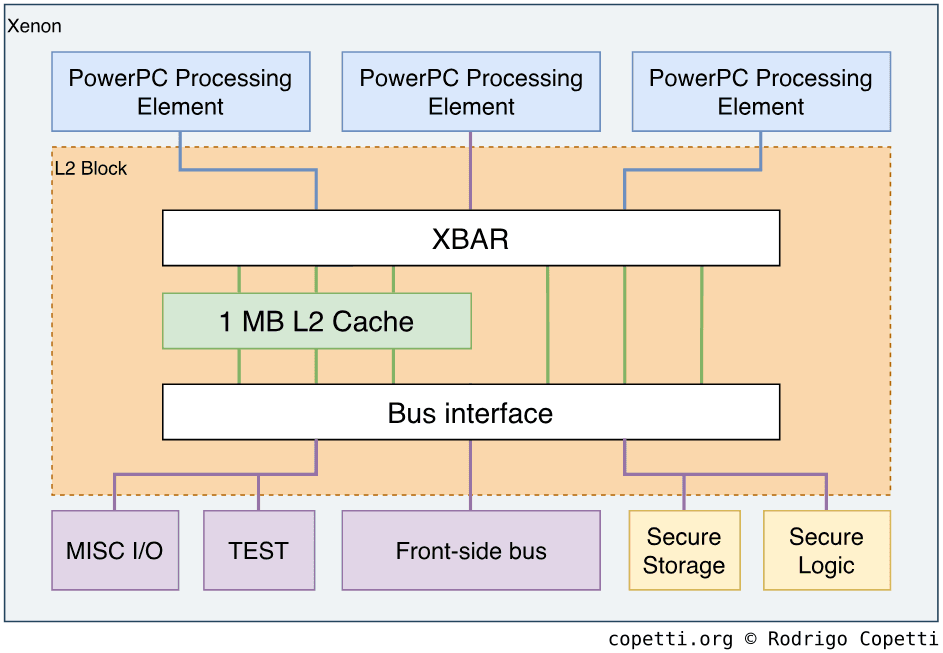
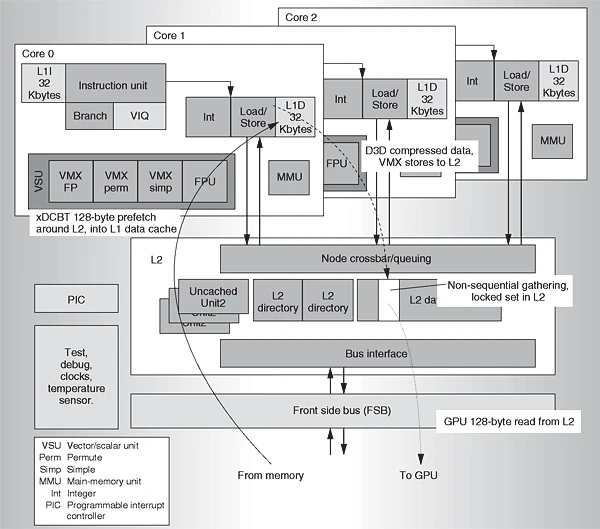
This model stands in stark contrast to the discrete memory architectures of most PCs. Consequently, the emulator cannot simply pass memory pointers between components. It must meticulously manage a single, coherent address space, translating and synchronizing data access to ensure correctness between the emulated CPU and the host's GPU, which typically operates on its own dedicated VRAM. This adds a constant layer of abstraction and complexity to all memory operations.
All of these factors compounded create a perfect-sh** storm for a real bad day for getting consistent emulation performance across all games released. This is where recompilation comes into play.
Enter XenonRecomp
Let me tell you about the beautiful toolset that is XenonRecomp. Developed by the hedge-dev team, this project represents the first successful static recompilation system for Xbox 360 games. What makes it special? Well, instead of interpreting PowerPC instructions on the fly like traditional emulators, XenonRecomp converts entire Xbox 360 executables directly into C++ code, which can then be recompiled for any x86 platform.
XenonRecomp processes encrypted and compressed XEX containers by first decrypting and decompressing them, then memory-mapping the executable sections into a virtual address space that mimics the Xbox 360's memory layout. This allows the recompiler to maintain the exact memory layout of the original system. Endianness conversion is handled systematically through helper macros:
#ifndef PPC_LOAD_U32
#define PPC_LOAD_U32(x) __builtin_bswap32(*(volatile uint32_t*)(base + (x)))
#endif
#ifndef PPC_STORE_U32
#define PPC_STORE_U32(x, y) *(volatile uint32_t*)(base + (x)) = __builtin_bswap32(y)
#endifThese macros ensure that all memory operations automatically convert between the big-endian source and the little-endian target environment.
Function Translation and State Management
The recompiler's core architecture operates on a direct translation principle: every PowerPC function becomes a C++ function. The instructions are translated directly into a sequence of C++ statements that manipulate a central processor context structure, which holds the state of all registers.
sub_82063A28:
stw r4, 28(r1)
lfs f0, 28(r1)
# ... more instructions disassembled ...
blrA disassembled PowerPC function
The instructions are directly converted without any effort to make them resemble the original source code, meaning the output is not very human-readable.
// The recompiler generates a C++ function for each PPC function
PPC_FUNC_IMPL(__imp__sub_82063A28) {
PPC_FUNC_PROLOGUE(); // Handles function entry logic
PPCRegister temp{}; // A temporary variable for intermediate calculations
// stw r4, 28(r1) --> Store word from register r4 to memory
PPC_STORE_U32(ctx.r1.u32 + 28, ctx.r4.u32);
// lfs f0, 28(r1) --> Load floating-point single into register f0
ctx.fpscr.disableFlushMode(); // Handle FPU state
temp.u32 = PPC_LOAD_U32(ctx.r1.u32 + 28); // Load the value we just stored
ctx.f0.f64 = double(temp.f32); // Convert & load into fpr
// ... more instructions translated ...
// blr --> Branch to Link Register (return)
return;
}Recompilation of sub_82063A28
Notice how every memory access goes through helper macros that handle endianness conversion?
Virtual Function Calls: The Perfect Hash
Now we get to the fun part – indirect branches and jump tables. These are the bane of static analyzers everywhere because you can't know where they'll jump until runtime. It's like trying to plan a road trip when the GPS keeps changing its mind about the destination.
Virtual function calls in Xbox 360 games present a unique challenge. Virtual function calls are resolved by creating a "perfect hash table" at runtime, where dereferencing a 64-bit pointer (using the original instruction address multiplied by 2) gives the address of the recompiled function:
// Original PowerPC virtual call pattern
lwz r12, 0(r3) // Load vtable pointer
lwz r12, 24(r12) // Load function pointer from vtable
mtctr r12 // Move to Count Register
bctrl // Branch to CTR and link
// XenonRecomp's translation based on the perfect hash approach
uint32_t vtable_ptr = PPC_LOAD_U32(ctx.r3.u32);
uint32_t func_addr = PPC_LOAD_U32(vtable_ptr + 24);
// Magic happens here - multiply by 2 to get recompiled function
uint64_t recompiled_func = *(uint64_t*)(func_addr * 2);
((void(*)(PPCContext&))recompiled_func)(ctx);Very simplified example of how the perfect hash is used
It relies on function addresses being placed after the valid XEX memory region in the base memory pointer.
Jump Table Detection and Translation
Jump tables are everywhere in compiled code – they're how switch statements typically get implemented. The problem is that they're incredibly hard to detect statically because they look like regular data until you try to execute them. XenonRecomp employs pattern recognition to identify these constructs:
# Classic Xbox 360 jump table pattern
loc_82070D40:
lwz r3, 0(r11) # Load some value
lwz r11, 0(r31) # Load switch variable
clrlwi r10, r11, 28 # Extract lower 4 bits (0-15)
addi r10, r10, -1 # Subtract 1 (now 0-8 range)
cmplwi cr6, r10, 8 # Compare with 8
bgt cr6, loc_82070F0C # Jump to default if > 8
# Here comes the jump table magic
lis r12, byte_82000F30@ha # Load jumptable base (high)
addi r12, r12, byte_82000F30@l # Load jumptable base (low)
lbzx r0, r12, r10 # Load byte offset from table
slwi r0, r0, 2 # Shift left 2 (multiply by 4)
lis r12, loc_82070D80@ha # Load code base (high)
addi r12, r12, loc_82070D80@l # Load code base (low)
add r12, r12, r0 # Calculate target address
mtctr r12 # Move to CTR
bctr # Jump!
#==============================================================================
# The jump table at byte_82000F30 contains byte offsets
# [0x25, 0x32, 0x11, 0x00, 0x63, 0x3E, 0x4A, 0x51, 0x58]
#
# After multiplication by 4, these map to:
# Index 0: offset 0x94 = case handler at loc_82070E14
# Index 1: offset 0xC8 = case handler at loc_82070E48
# Index 2: offset 0x44 = case handler at loc_82070DC4
# Index 3: offset 0x00 = case handler at loc_82070D80
# Index 4: offset 0x18C = default case at loc_82070F0C
# Index 5: offset 0xF8 = case handler at loc_82070E78
# Index 6: offset 0x128 = case handler at loc_82070EA8
# Index 7: offset 0x144 = case handler at loc_82070EC4
# Index 8: offset 0x160 = case handler at loc_82070EE0
#==============================================================================XenonAnalyze detects these patterns and generates a configuration file for all jump tables it can detect.
[[switch]]
base = 0x82070D58 # Where the jump table logic starts
r = 10 # Register holding the switch index
default = 0x82070F0C # Default case address
labels = [ # All possible jump targets
0x82070E14, # Case 0
0x82070E48, # Case 1
0x82070DC4, # Case 2
0x82070D80, # Case 3
0x82070F0C, # Case 4 (default)
0x82070E78, # Case 5
0x82070EA8, # Case 6
0x82070EC4, # Case 7
0x82070EE0, # Case 8
]The recompiler then transforms this entire mess into a simple C++ switch statement:
loc_82070D40:
// ... register setup code ...
// lbzx r0, r12, r10 - Load jump table entry
ctx.r0.u64 = PPC_LOAD_U8(ctx.r12.u32 + ctx.r10.u32);
// slwi r0, r0, 2 - Convert byte offset to address offset
ctx.r0.u64 = (ctx.r0.u32 << 2);
// ... address calculation ...
// The magic: replace computed jump with switch statement
switch (ctx.r10.u64) {
case 0: goto loc_82070E14; // Jump to case 0 handler
case 1: goto loc_82070E48; // Jump to case 1 handler
case 2: goto loc_82070DC4; // Jump to case 2 handler
case 3: goto loc_82070D80; // Jump to case 3 handler
case 4: goto loc_82070F0C; // Jump to default handler
case 5: goto loc_82070E78; // Jump to case 5 handler
case 6: goto loc_82070EA8; // Jump to case 6 handler
case 7: goto loc_82070EC4; // Jump to case 7 handler
case 8: goto loc_82070EE0; // Jump to case 8 handler
default:
__builtin_unreachable(); // Should never happen
}Beautiful, isn't it? We've turned low-level pointer arithmetic into high-level control flow that any C++ compiler can optimize the hell out of.
Composing VMX128 Decompositions using x86 Intrinsics
The translation of the VMX128 vector instructions represents one of the most complex aspects of the recompilation process. The architectural mismatch between the PowerPC's 128 vector registers per thread and x86's limited vector register set requires creative solutions.
See the problem?
No...? Well S***...
Let's look at the quintessential example of this issue. The permute problem.
The vec_perm instruction is VMX's Swiss Army knife – it can arbitrarily shuffle bytes between two vectors using a control vector. SSE has nothing comparable, requiring creative decomposition using the available intrinsics.
inline __m128i _mm_perm_epi8_(__m128i a, __m128i b, __m128i c)
{
__m128i d = _mm_set1_epi8(0xF);
__m128i e = _mm_sub_epi8(d, _mm_and_si128(c, d));
return _mm_blendv_epi8(_mm_shuffle_epi8(a, e),
_mm_shuffle_epi8(b, e),
_mm_slli_epi32(c, 3));
}XenonRecomp/XenonUtils/ppc_context.h
The function operates through three key transformations.
First, it creates a mask vector d containing 0x0F in every byte position, which serves as the boundary between the two source vectors.
Second, it computes e by masking the control vector with 0x0F and subtracting from 0x0F, effectively reversing the byte indices within each 16-byte vector. This reversal compensates for the endianness difference between PowerPC's big-endian and x86's little-endian architectures.
The final blend operation represents the culmination of this translation. The function uses _mm_shuffle_epi8 to independently shuffle both input vectors according to the reversed indices stored in e. It then employs _mm_blendv_epi8 to select between these shuffled results. The blend mask is generated by shifting the control vector left by 3 bits, which examines bit 4 of each byte in the original control vector to determine whether that byte should come from vector a or vector b.
This implementation elegantly handles the endianness conversion and selection logic between the two source vectors, demonstrating how static recompilation can transform architectural mismatches into optimized native code sequences during the compilation phase.
Performance Analysis and Comparative Advantages
Static recompilation provides substantial performance advantages over dynamic emulation systems. Where dynamic binary translation through JIT typically requires 15-17 host instructions per guest instruction on average, XenonRecomp's static approach eliminates this overhead entirely by executing pre-compiled native code.
The project achieves significant reduction in processor cycle overhead compared to dynamic translation systems while maintaining compatibility. These improvements result from eliminating runtime translation overhead and allowing the native C++ compiler to apply advanced optimization techniques to the translated code.
Conclusion
XenonRecomp represents a significant achievement in static binary recompilation technology, successfully addressing the complex technical challenges inherent in Xbox 360 PowerPC to x86 translation. The project demonstrates that static recompilation can achieve superior performance compared to dynamic emulation while maintaining complete software compatibility.
The techniques developed for this implementation—particularly in handling the extensive register architecture, unified memory model, and complex vector instructions—establish static recompilation as a viable approach for software preservation and modernization across complex computing platforms. This work provides a foundation for future efforts aimed at migrating other legacy systems to contemporary hardware architectures without sacrificing performance or compatibility.
Take it easy,
Tom
Additional Resources:
- XenonRecomp Project: https://github.com/hedge-dev/XenonRecomp
- Unleashed Recompiled: https://github.com/hedge-dev/UnleashedRecomp
- N64: Recompiled: https://github.com/N64Recomp/N64Recomp
- Super Smash Bros: Recompiled: https://github.com/zestydevy/smash64r
- Xenia - https://github.com/xenia-project/xenia

